April 3, 2022
Kubernetes の設計思想を理解する
こんにちは。皆さん、Kubernetes は好きですか?
今日は、皆さんが (恐らく) 大好きな Kubernetes について、4 つの設計原則を概観しながら、その設計の背景にある基本的な考え方を見ていきます。特に、"なぜ?" を中心に議論することで、Kubernetes に関する理解を深め、その人気の理由を紐解いていきたいと思います。
なお、この記事の内容は KubeCon + CloudNativeCon 2020 の発表 と Programming Kubernetes を参考にしています。英語が苦でない方は、ぜひこちらも参照してみてください。
では、早速 Kubernetes の 4 つの設計原則を見ていきましょう。
設計原則 1 : "宣言的" な API を提供する
まず、命令的 (imperative) な API を利用した場合を考えてみましょう。
命令的な API では、ユーザーは "目的の状態を達成するために必要な処理手順" をシステムに伝えます。例えば、コンテナアプリケーションを実行したい場合、"ノード B でこのコンテナを起動してください" などと伝えます。


このとき、
- コンテナがクラッシュしたらどうなるでしょうか?
- ノードがダウンしたら?
- 命令したタイミングで、ノード B が一時的に不安定だったら? (一時的なネットワーク障害など)
これらの状況下でもアプリケーションを正常に実行するためには、ユーザーはアプリケーションの状態を監視し、問題があれば復旧処理を行うカスタムロジックを実装しなければならないでしょう。これは、アプリケーションを安全に実行するために、多くの開発コストが必要になることを意味します。
一方、Kubernetes では、宣言的 (declarative) な API を提供します。つまり、ユーザーは "目的の状態を達成するために必要な処理手順" を伝えるのではなく、"目的の状態" をシステムに伝えます。コンテナアプリケーションを実行したい場合には、"この Pod (コンテナ) が 1 つ実行している状態にしたいです、あとはお任せします" などと伝えることになります。
より具体的には、Kubernetes では、ユーザーは "目的の状態" を反映した API オブジェクトを作成し、API Server (の背後にある etcd と呼ばれる分散 KVS) にその情報を保存します。(コンテナアプリケーションを実行する場合には、ReplicaSet (Deployment) を作成しますよね?) API オブジェクトが作成されると、Kubernetes は "目的の状態" を達成するのに必要な手順を計算し、各コンポーネントがそれぞれの責務を実行します。

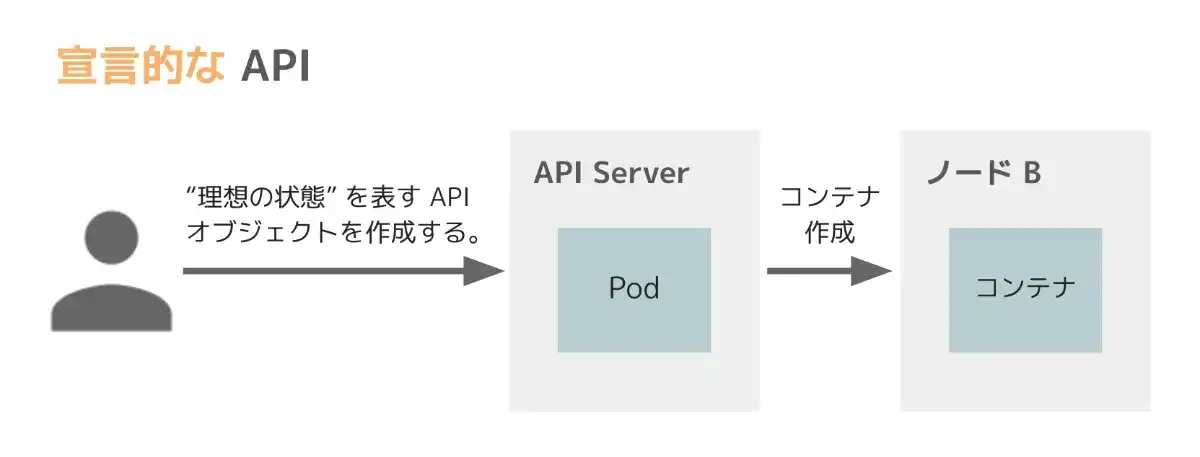
このような宣言的な API では、ユーザーはアプリケーションの状態を監視したりする必要はありません。宣言的な API の大きなメリットの 1 つは、アプリケーションやノードの障害からの自動復旧能力です。例えば、あるノードがダウンした場合にも、API Server には "目的の状態" が記録されているので、Kubernetes はそのノード上にあった Pod を別の正常なノードで実行し直すことで、"目的の状態" に自動で復旧することが可能となります。宣言的な API を用いることで、ユーザーは大部分を Kubernetes に任せた形で自動復旧を実現できるのです。
設計原則 2 : level-driven な仕組みを持つ
では、API オブジェクトが作成されたとき、Kubernetes の各コンポーネントは自身の責務をどのように知るのでしょうか? 例えば、各ノードは自身が実行すべきワークロードをどのように知るのでしょうか?
シンプルに考えると、どのノードでどの Pod を実行すべきか計算したあと、API Server が各ノードに対して "このコンテナを起動してください" と命令する方法が考えられます。前章で見た命令的な API と同じ方法で、API Server が各コンポーネントに対して "目的の状態を達成するために必要な処理手順" を伝える方法です。このようなパターンでは、"状態の変化" に関する情報のみが伝えられるため "edge-driven" と形容されます。

しかし、この方法だと、命令的な API の場合と同じ問題が発生します。(もしアプリケーションやノードに障害が発生した場合、どうなるでしょう?) アプリケーションを安全に実行するためには、API Server は各コンポーネントの状態を常に監視し、障害を見つけたら復旧処理を行う必要が生じます。そのため、API Server が全てのワークロードに関する責任を持つことになり、どんどん複雑になります。また、安全にワークロードを実行するための全ての情報が API Server に集約され、肥大化していきます。
そこで Kubernetes では、API Server が必要な手順を各コンポーネントに伝えるのではなく、各コンポーネントが API Server (内の API オブジェクト) の "状態" を確認することで自身の責務を把握します。このパターンでは、アクセスしたタイミングの API Server の "状態" に応じて各コンポーネントが動作するため、"level-driven" と形容します。


具体例を見ながら、この方式について整理しましょう。ある Pod を 1 つ実行することを考えると、Kubernetes の各コンポーネントは以下のように動作します。
- ユーザーが Pod を作成すると、
spec.nodeNameが空の Pod が API Server に記録されます。 - スケジューラーが API Server の状態を確認し、
spec.nodeNameが空の Pod を見つけ、実行するのに最適なノードを計算してspec.nodeNameを更新します。 - 各ノード上で動いているエージェント (kubelet) が API Server の状態を確認し、
spec.nodeNameと自身のノード名が一致する Pod を見つけ、実際にコンテナを起動します。
このように、Kubernetes では、各コンポーネントは API Server の "状態" によって、自身の責務を知るのです。

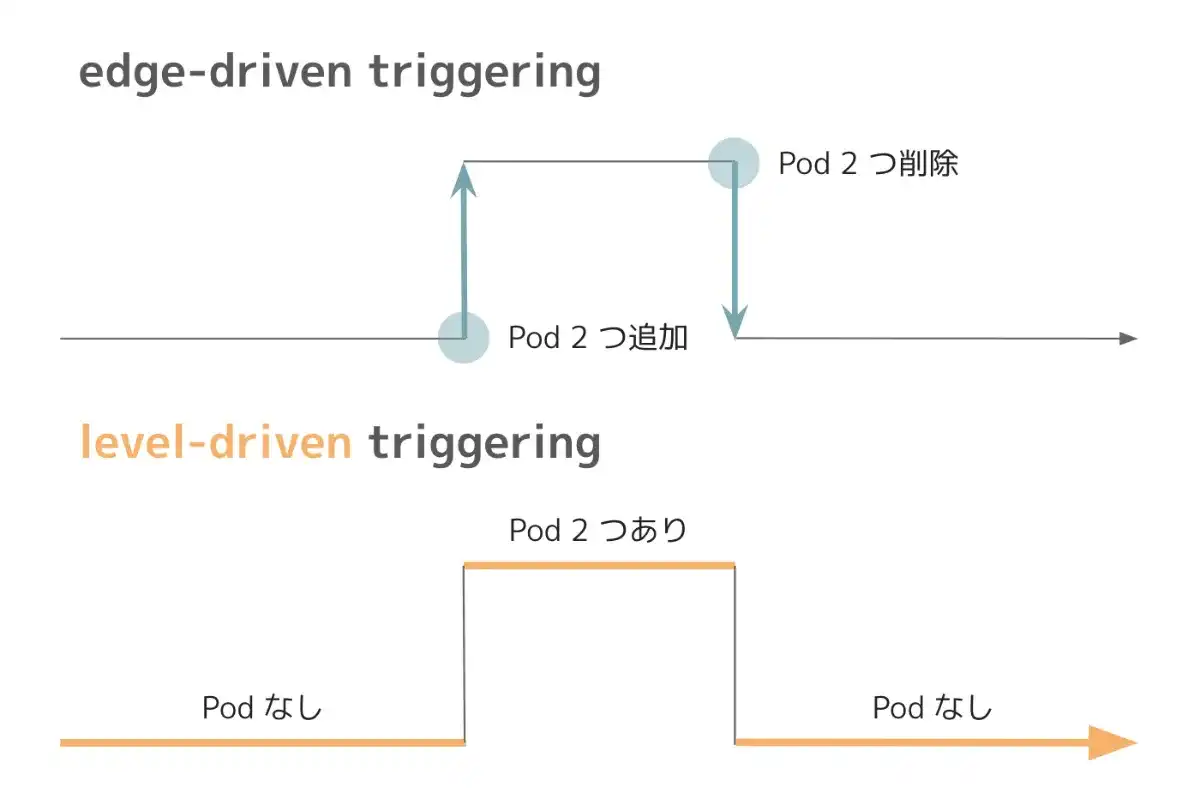
分散システムを構築する場合、システムが大きくなっていくにつれ、コンポーネントの障害は避けられなくなっていきます。そのため "design for failure" なシステム設計が必要になります。"edge-driven" なパターンでは、障害が発生すると情報が失われてしまうのに対し、"level-driven" なパターンでは、あるコンポーネントに一時的な障害が発生したとしても、復旧後 API Server の "目的の状態" を確認することで、障害から容易に復旧できます。また API Server に障害が発生したとしても、各コンポーネントは最後に見た "目的の状態" に基づいて責務を実行し続けることが可能です。すなわち、分散システムにおいて、"level-driven" な仕組みを持ち、責務を各コンポーネントに分散させることで、単一障害点を無くすことができます。
また、API Server は、各コンポーネントを監視・復旧させる必要がなくなるため、責務が大幅に削減され、簡素化されます。Kubernetes の全てのコンポーネントは、ユーザーが利用するのと同じ API を通じて API Server と通信するため、この API を用いたカスタムロジックを実装することで、Kubernetes の機能そのものも容易に拡張できます。この "拡張性の高さ" こそが、多くのワークロードで Kubernetes が採用されている理由の 1 つと言えるでしょう。
余談 : API Server がコンポーネントに "手順" を伝えるのではなく、コンポーネントが API Server の "状態" を確認することで自身の責務を知る、ということは分かりました。では、いつ API Server の状態を確認するのでしょうか?
"定期的に API Server にアクセスする" のでは、ユーザーの要求が満たされるまでの時間はポーリングの間隔に依存します。その間隔を短くしたとしても、コンポーネントがスケールするにつれ API Server の負荷が増大し、ユーザーを待たせてしまうことになるでしょう。そこで、Kubernetes では "API オブジェクトが変更されたタイミング" と "定期的に" の両方で API Server の状態を確認する方法を採用しています。これにより、ユーザーの要求を素早く満足しつつ、自動復旧も実現できます。
また、Kubernetes では "API Server に直接確認しにいく" のではなく、"API Server の状態を反映したインメモリキャッシュに確認しにいく" 方法を採用しています。さらに、このインメモリキャッシュの仕組みが成熟した結果、定期的なキャッシュ同期の際には API Server にアクセスしない実装に変更されています。定期的に API Server にアクセスしなくても、API Server のイベントを watch することで、十分正確に状態をキャッシュできるようになったのですね。
より詳細な仕組みは、Programming Kubernetes を参照してください。
設計原則 3 : Kubernetes への移行を容易にする
次に、アプリケーションを実行するのに "設定パラメータ" や "認証情報" が必要な場合を考えてみましょう。例えば、外部サービスのエンドポイントやデータベースの認証情報などが必要になるとします。このとき、アプリケーションをコンテナ化する際、特にセンシティブな認証情報はコンテナイメージの外に持つのが原則です。これらの情報は、コンテナ起動時に外から挿入することで、認証情報が漏れてしまう可能性を削減できます。(コンテナの可搬性の観点から、認証情報だけでなく各種の設定もコンテナイメージの外に持つことが推奨されます。)
では、Kubernetes 上で動くアプリケーションでは、これらの情報をどのように取得するのでしょうか? Kubernetes では、これらの設定や認証情報を、ConfigMap や Secret と呼ばれる API オブジェクトに保持します。もちろん、これらの情報には Kubernetes の API を介してアクセスできるので、"API Server から情報を読み取るようにアプリケーションを改修する" 方法が考えられます。


しかし、Kubernetes では、この方法は取りません。なぜなら、前述の方法では "Kubernetes に移行するためにアプリケーション改修のコストがかかる" ことを意味するからです。多くのアプリケーションでは、設定や認証情報を "ファイル" や "環境変数" の形で読み取るよう実装されているでしょう。そこで Kubernetes では、最小限の改修で Kubernetes に移行できるよう、ConfigMap や Secret の情報を、コンテナ起動時に "ファイル" や "環境変数" の形でコンテナに挿入できるように実装されているのです。


設計原則 4 : ワークロードの可搬性を担保する
最後に、コンテナの外部ストレージについて考えてみましょう。コンテナは、終了時に内部に保持しているデータを破棄してしまうので、コンテナのライフサイクルよりも長くデータを保持したい場合には、外部ストレージを利用することになります。外部ストレージとしては、ノード上のストレージを利用したり、AWS EBS や GCE PD など、クラウド上のストレージを利用できます。
では、Kubernetes 上で動くアプリケーションでは、どのように外部ストレージを利用するのでしょうか? シンプルには、Pod 定義で "AWS EBS の gp3 ボリュームを 20 GB 利用したい" などと定義することが考えられます。この方法だと、Pod がノードにスケジュールされた後、ボリュームのアタッチ・デタッチを担うコンポーネントが、必要なボリュームをノードにアタッチすることで、外部ストレージを利用できます。

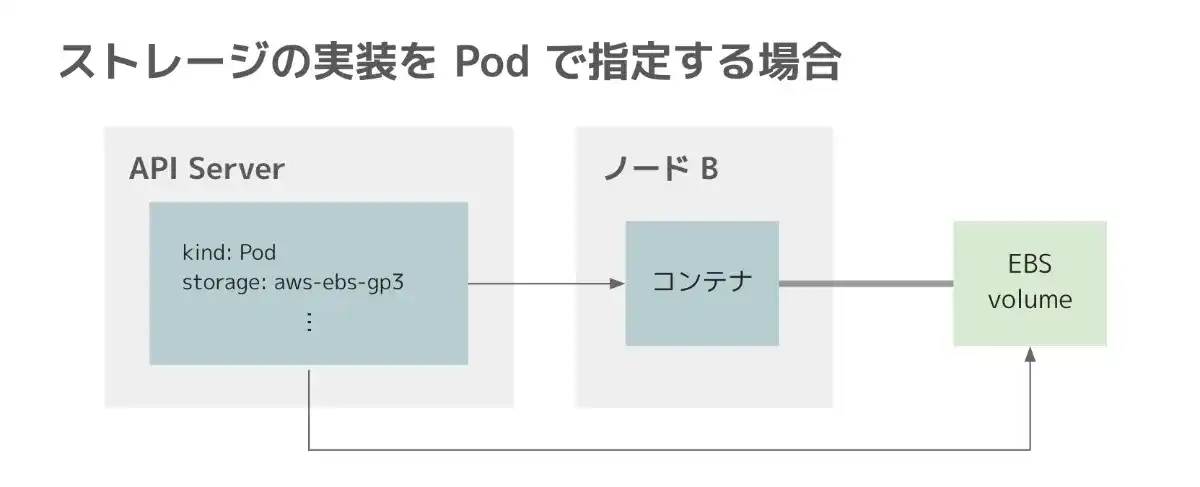
しかし、Kubernetes では、この方法は取りません。なぜなら、この方法では AWS 上では正常に動作したとしても、同じ Pod 定義をオンプレミスでは利用できない、すなわち、ワークロードの可搬性が損なわれてしまうからです。Kubernetes では、AWS で動くワークロードは GCP やオンプレミスでも同様に動くことが期待されます。したがって、Pod 定義の中で特定のタイプのボリュームを参照すべきではないのです。
そこで、Kubernetes では、API オブジェクトによって、"ストレージの要求" と "具体的なストレージの実装” を分離します。まず、ユーザーは PersistentVolumeClaim (PVC) と呼ばれる API オブジェクトを作成し、要求するストレージの一般的な情報 (容量やアクセスモードなど) を保持します。一方、クラスターの管理者は、実際に利用可能なストレージを定義する PersistentVolume (PV) と呼ばれる API オブジェクトを事前に作成しておきます。そうすることで、PVC が作成されたタイミングで、PV Controller と呼ばれるコンポーネントが PVC の要求を満たす PV を探し出し、ストレージを割り当てることができます。

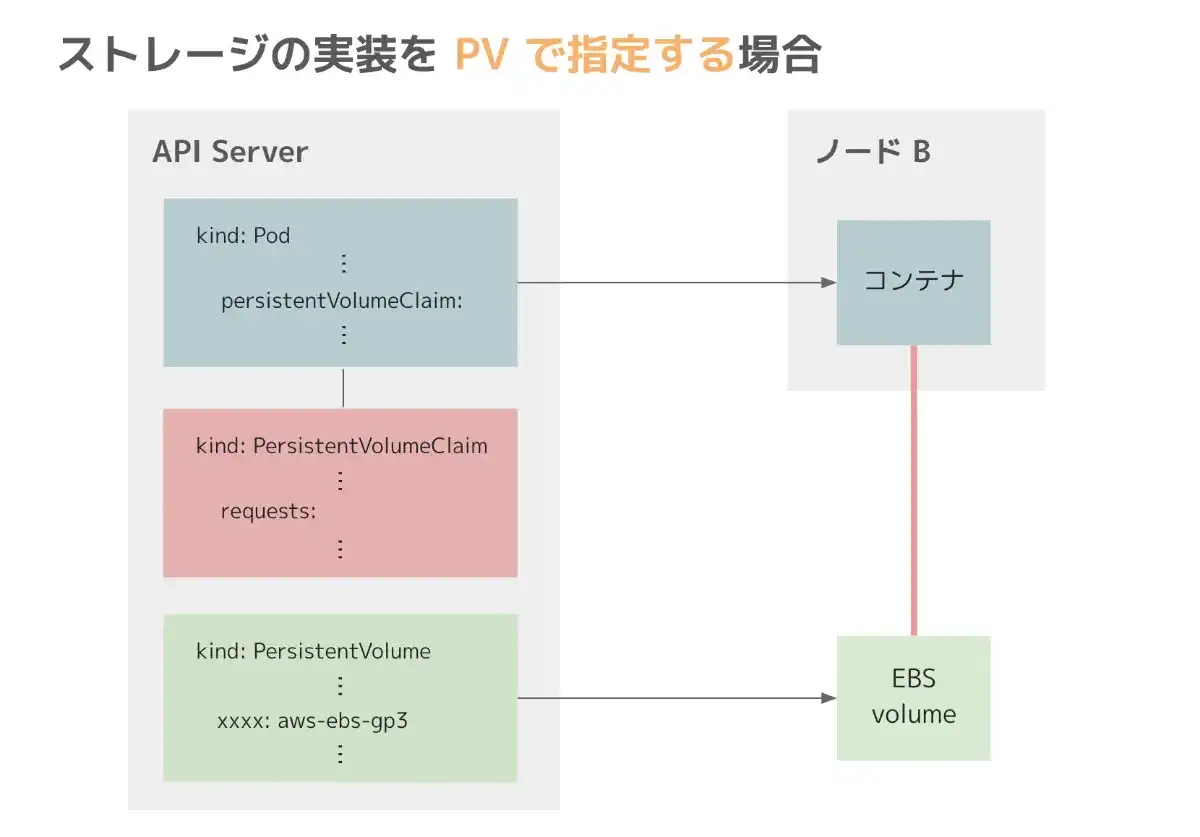
もしくは、管理者は PV を作成する代わりに、"どのように新しいストレージを作成するか" を定義した StrageClass (SC) と呼ばれる API オブジェクトを作成することも可能です。管理者がどの環境でも同じ名前の SC を作成しておくことで、ユーザーは PVC で SC を参照して、Pod が起動した時に SC の定義にしたがって新しくストレージを作成できます。(SC を利用する場合、PVC が作成されたタイミングで背後で PV が動的に作成されます。)
このように、PV / SC どちらを利用した場合でも、ストレージの要求と実装を分離して抽象化することで、ユーザーが利用する API オブジェクト (この場合は Pod と PVC) は可搬性を持つことが可能になります。つまり、どのような環境 (クラスター) においても、同じようにワークロードを実行できるようになるのです。可搬性は、Kubernetes の普及を支えてきた重要な特性の 1 つです。
まとめ
この記事では、Kubernetes の 4 つの設計原則を概観しながら、"宣言的 API"、"level-driven"、"移行容易性"、"可搬性" など、Kubernetes の持つ特性について学びました。この記事を読んで、もっと Kubernetes のことを好きになってくれたら嬉しいです。
では、また。
この記事をシェアする